Evaluation in Natural Language Processing (NLP) is tricky. It is especially tricky with the advent of incredibly large language models that are generally pretrained on web corpora and it is often difficult to characterize and understand the data distribution of the training data. In this post, I want to talk about a fundemental challenge in NLP evaluation with examples and what we can do about it. We will use tools from differential geometry to highlight the incredible complexity of this task and how many of the current approaches ignore the manifold of output probability distribution. Consequently most evaluation paradigms that are trying to create complex test sets manually are just ineffective and not useful.
If this is useful, please cite the paper here: https://proceedings.mlr.press/v196/datta22a.html
Understanding classifier fragility by perturbing examples
Artifical intelligence is the phenomenon of this decade. Wide ranging applications of artificial intelligence have been using artifical intelligence in a wide variety of domains like healthcare, self-driving vehicles and speech recognition mostly because of the rapid explosion in the data and computation available in these fields. At the heart of this progress are Neural networks which are incredibly good at classification. They are used in a wide variety of applications with human-level accuracy 1 in object classification, detecting cancer from X-rays 4, and translating text across languages 5. Deep learning’s impact in our day to day life is hard to argue but there still remains a variety of unanswered questions about the underlying principles and limitations of deep learning. We know about existence of adversarial examples in deep learning, where minor changes in the background context of the images can alter the predicted labels. There have been cases where deep learning models can generate captions from an image even without looking at the image. These highlight the limitations of these models and can impact in adverse ways different segments of data and populations. In this blog we will discuss the possible explanations, some existing work and the current limitations of these evaluation approaches.
Biased datasets?
While a lot of the problem is often framed as dataset issue, the issue is a little more complex than that. The most widely used dataset for image classification, ImageNet, which accounts for only 4% of the world population contributed to 45% of the images in this dataset. While trying to create balanced dataset is an ambitious challenge and companies are actively investing in this area there are inherent issues with this approach. In multiple situations it may not be possible to create balanced datasets. Cultural contexts, societal norms prevent collection of such balanced datasets. This paper provides a fantastic history of the ImageNet dataset and this post highlights some of the known biases.
While these are active research areas, this problem has other implications. Suppose you have completely balanced datasets, like the IMDb sentiment analysis dataset. A dataset with positive and negative movie reviews. 25000 positive and 25000 negative movie reviews. When you train a neural network classifier you are inherently creating a decision boundary. See the diagram below. By design, there will be examples that are close to the decision boundary and some far from it. In fact, the red example is farther from the decision boundary than the blue example. Now suppose you are trying to tweak the red example in such a way so that you alter the class. Think of this as slowly altering each word in a movie review such that the sentiment of the movie review changes from positive to negative. It is clear from the diagram below that you need to tweak the blue example only a little, but for the red example you have to tweak quite a bit. Then are these examples equally robust to different types of tweaks or perturbations? Also, assuming you have a movie review, will changing the positive words to negative words change the classifier prediction? This is definitely something that we want. However there are other issues worth exploring. Will changing the name of an actor in a movie review change the prediction? How about the situation when we change all the positive words to negative words and the movie review still remains positive. This is definitely problematic. In the rest of this article we will answer some of these questions using tools of information geomtery. We will breifly describe it in the context of neural networks and then give examples in the IMDb movie reviews dataset.
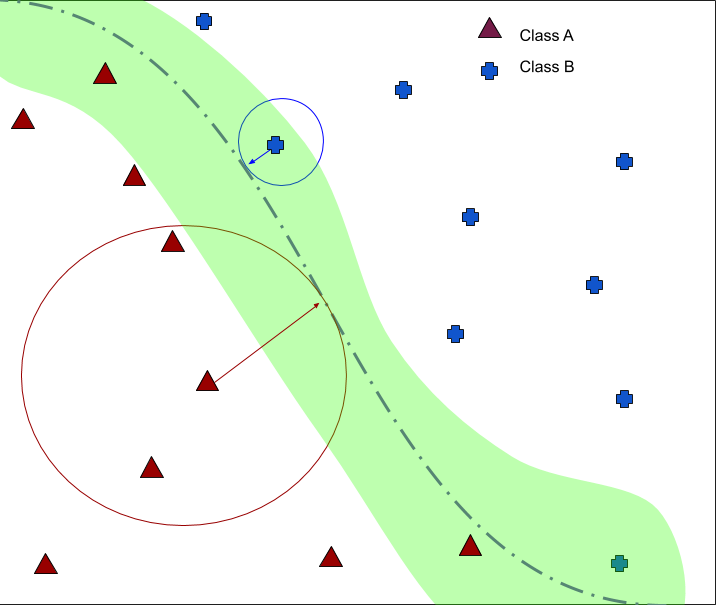
Understanding Perturbations
The output of the neural networks are probability distributions over labels (eg cat, dog, rabbit = [0.1, 0.5, 0.4]). The set of all possible distributions like these forms something we call a simplex (red triangle). A neural network with a fixed set of weights forms a subset of this space. This is shown with the blue ellipse.
Now let’s consider what happens when we perturb a data point in input space: eg 𝑋2 -> 𝑋2′ . As can be seen in the schematic to the right, the distribution over labels doesn’t really change much in the case of 𝑋2 (orange histograms, right). However, if we try to perturb another data point 𝑋1 by a small amount, the distribution over labels changes completely (purple histograms, right). We can see that the mapping is sensitive to changes in input in the second case and a small change can cause the classifier to predict something else. For the rest of the article we will refer to this as fragility of the example.
Well, how do we measure such sensitivity? Interestingly, information geometry provides us with a tool called the fisher metric to study such mappings and the sensitivity w.r.t the parameters (here the input 𝑋 ). Just like we can talk about distances and lengths between vectors, the fisher metric allows us to define lengths and distances between two probability distributions lying on the red manifold.
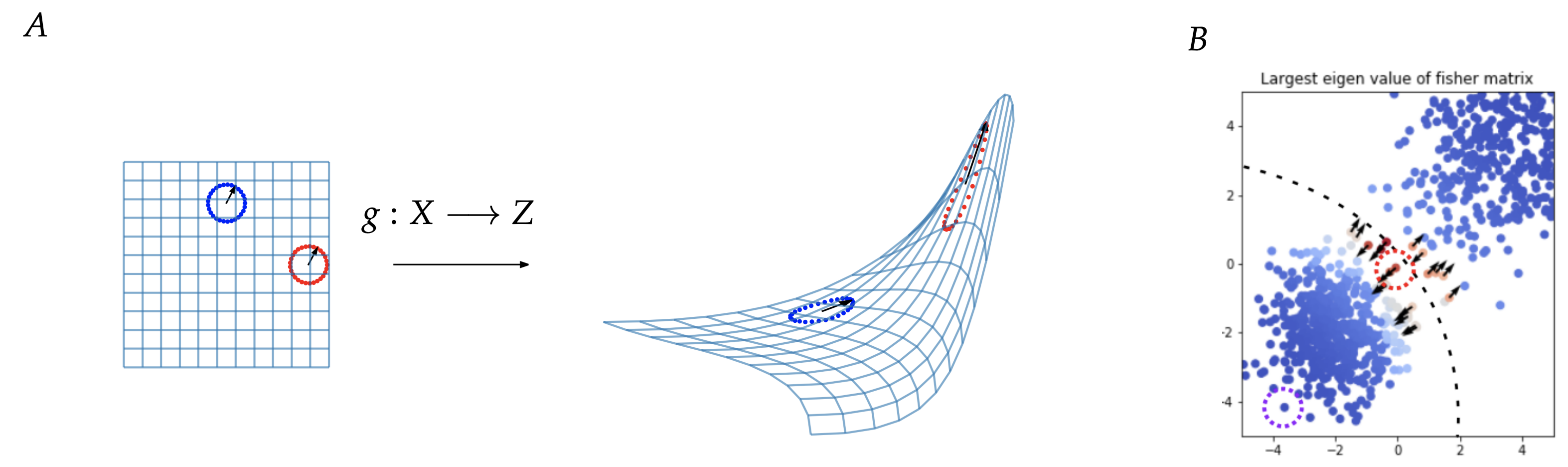
Now that we have some intuition about the fisher metric, let’s see a case study of it. We first investigate the FIM properties by training a neural network on a synthetic mixture of Gaussians dataset. The parameters of the two Gaussians are 𝜇1=[−2,−2] and 𝜇2=[3.5,3.5] . The covariances are Σ1=𝑒𝑦𝑒(2) and Σ2=[[2.,1.],[1.,2.]] The dataset is shown in figure below. We train a 2-layered network to separate the two classes from each other. We compute the largest eigenvalue of the FIM for each data point and use it to color the points. We also plot the eigenvector for the top 20 points.
As seen by the gradient of the colors in Figure 1, the points with the largest eigenvalue of the FIM lie close to the decision boundary. These points are indicative of how confusing the example is to the neural network since a small shift along the eigenvector can cause a significant change in the KL divergence between the probability distribution of the original and new data points. These points with a high eigenvalue are close to the decision boundary, and these examples are most susceptible to perturbations.
How it translates to evaluation in Natural Language Processing
Sentiment Analysis
No task has been studied in Natural Language Processing as much as sentiment analysis. In sentiment analysis task a two class classification problem to classify a movie review to positive and negative reviews. So an easy example of such a review can be “This movie is excellent! I loved it.” This movie review is clearly positive. If we wanted to tweak this movie review to make it negative we would change the words “excellent” to “terrible” and “loved” to “hated”. Movie reviews are generally long and tweaks can be very involved. Take the following example from the IMDb movie reviews dataset.
Going into this movie, I had heard good things about it. Coming out of it, I wasn’t really amazed nor disappointed. Simon Pegg plays a rather childish character much like his other movies. There were a couple of laughs here and there– nothing too funny. Probably my favorite parts of the movie is when he dances in the club scene. I totally gotta try that out next time I find myself in a club. A couple of stars here and there including: Megan Fox, Kirsten Dunst, that chick from X-Files, and Jeff Bridges. I found it quite amusing to see a cameo appearance of Thandie Newton in a scene. She of course being in a previous movie with Simon Pegg, Run Fatboy Run. I see it as a toss up, you’ll either enjoy it to an extent or find it a little dull. I might add, Kirsten Dunst is adorable in this movie. :3
It might take a while to understand if this movie review is positive or negative. The ground truth data label for this is positive and it does appear to convey a positive sentiment. If you had to guess if this movie review is clearly positive vs somewhat positive, you will most likely chose “somewhat positive”. In other words, you are intuitively thinking about the decision boundary logic we discussed above. This movie review is closer to the decision boundary but is still on the positive side of the decision boundary. You can tweak some words and this can become a negative review. What is problematic however is if you change the name of the actor “Kristen Dunst” and that changes the movie review from positive to negative sentiment. A human being will never make such a mistake.
How do we tweak a sentence?
An important question to think about is to understand how to tweak the sentence. Imagine you reading a movie review.
“The movie is excellent. The actor was wearing a blue t-shirt and was wearing green shoes.”
In this review, if someone asked you how you determined the movie review to be positive, you will most likely mention the word “excellent” to determine the review. It is thus important to tweak the word excellent to alter the movie review from positive to negative and not the other words. This has two implications. One tweaking “neutral” words should not change the movie review, think about the “Kristen Dunst” example above and changing the positive words should alter the movie review. If “excellent” changes to terrible, we want the movie review to change.
In neural networks and especially in NLP there are multiple techniques to understand which words the movie review relies on. One such technique is known as Integrated Gradients. This approach has multiple strengths over other interpretabilitily techniques. It satisfies, sensitivity (Is it looking at the relevant features to classify?) and Implementation Invariance (If two neural networks are functionally equivalents, the attributions should be identical as well). If these seem like obvious requirements for a neural network interpretability you are right. These should be fundemental requirements in understanding a prediction from a classification task.
In our examples, we will use Integrated Gradients to highlight the words the model is looking at and then tweak only those words. This helps prevent tweaking words that are not important and helps to focus on the task at hand.
What is the model?
A convolutional neural network (CNN) with a 50d GloVe embedding on the IMDB dataset. The model is a simple text classification model and a detailed approach on how this works has been described here in this blog post with lots of images. We also show that with LSTM and BERT based models.
Analyzing IMDb sentiment through the Fisher Metric?
As we discussed above the Fisher metric gives us information about how far an example is from the decision boundary. If the example is closer to the decision boundary it will have a high value of the fisher metric and if it is far from the decision boundary the value will be small. We compute the fisher metric for each IMDb movie review and discuss the impact of perturbation in a sentence based on the value of the Fisher Metric.
So only examples near the decision boundary matter?
Yes and no. Examples near the decision boundary, which we will call difficult examples are the ones that are most fragile to changes. But examples far away from the decision boundary are susceptible to another kind of problem. Sometimes you can change all the positive words and the output labels still do not change. This is also an issue since we expect the movie review to change if all positive words have been changed to negative or viceversa.
Difficult examples, are examples that are close to the decision boundary. Here very subtle changes make a difference. Like meaningless changes like names of actors change the movie review. Easy examples are the ones that require significant edits to change a movie review. As we will see, in easy examples, even with multiple simultaneous edits movie reviews do not change whereas in difficult examples a single meaningless change flips the classifier prediction.
How has this problem been addressed?
Most approaches are based on heuristics. Contrast sets and Counterfactual examples are two approaches that came out in the last few years and both of them are based on humans perturbing the examples to create examples near the decision boundary.
As you may have guessed by now, both of these approaches are not effective in finding examples near the decision boundary but instead just rely on the new data distribution that is used to train the classifier. This creates the illusion that the approach is seemingly working on the small subsample and fails to generalize broadly.
In the subsequent examples, we highlight a variety of examples from IMDB dataset on the use of the fisher information based approach. Hopefully this will illustrate to you the complexity of natural language evaluation.
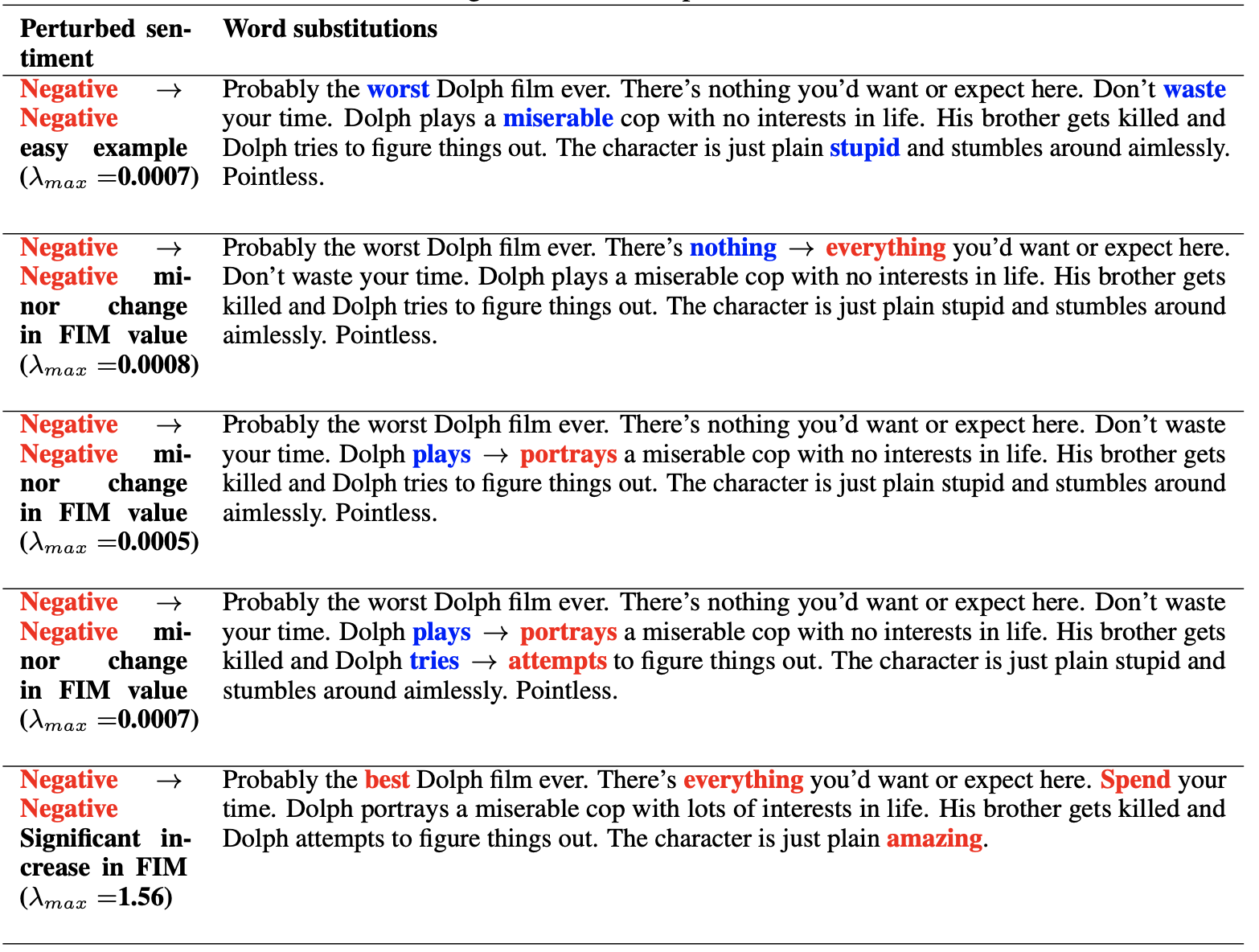
CNN model (50d GloVE embedding) where the blue word is substituted with one of the example red words and the corresponding prediction change is shown in the left diagram.

Here, examples that are far away from the decision boundary and perturbed with word substitutions showing that the prediction does not change despite significant word substitutions.
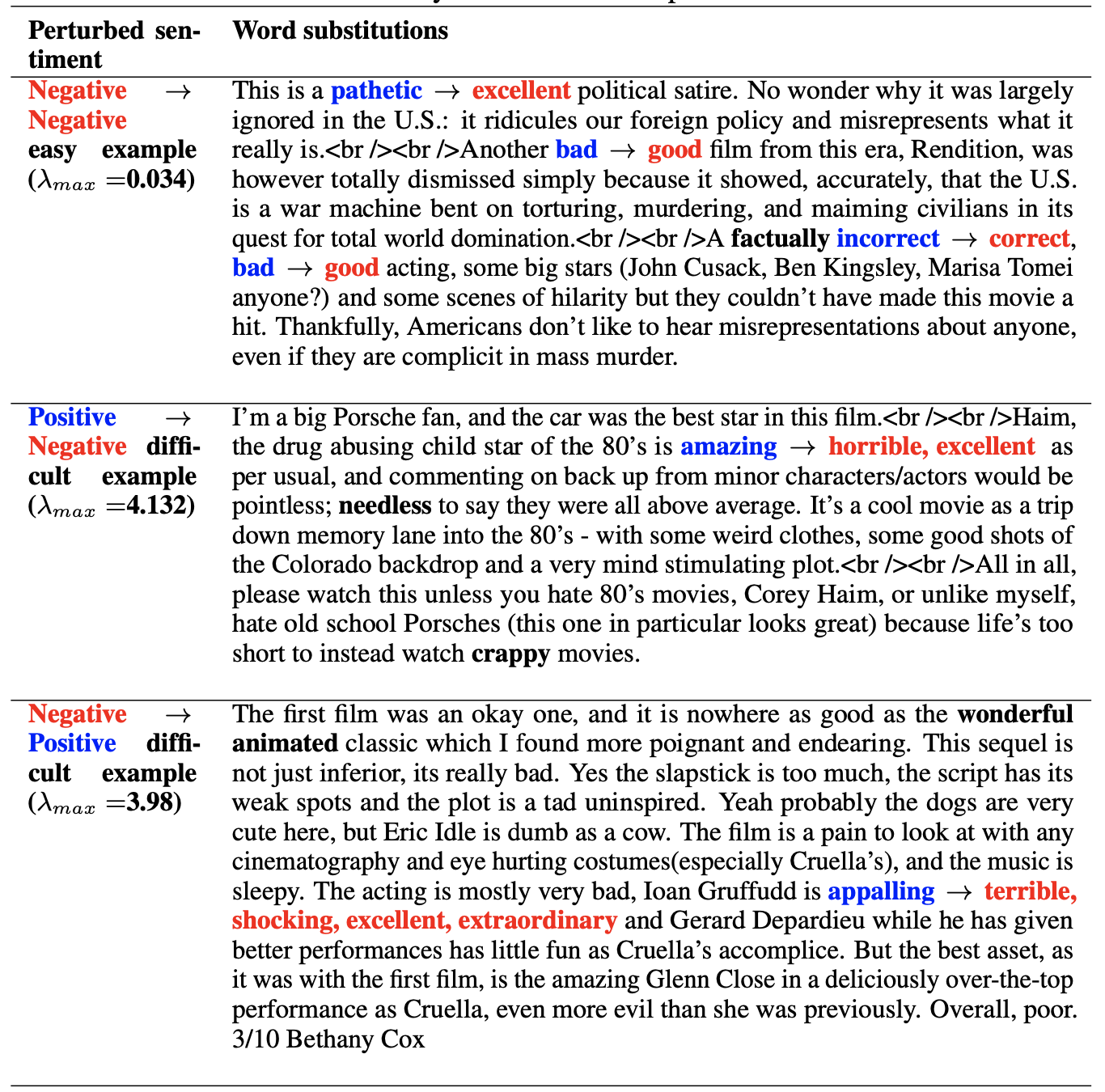
The same phenomenon persists when we use counterfactual explanation dataset and the contrast set datasets highlighting manual interventions do not make a difference and it is difficult to understand and quantify examples that are close to the decision boundary.

Please reach out if you have any questions, suggestions or extentions. You can also read our paper in detail here: https://proceedings.mlr.press/v196/datta22a.html